Frits Hermans
Home
About
Data science blog
Aggregation learning
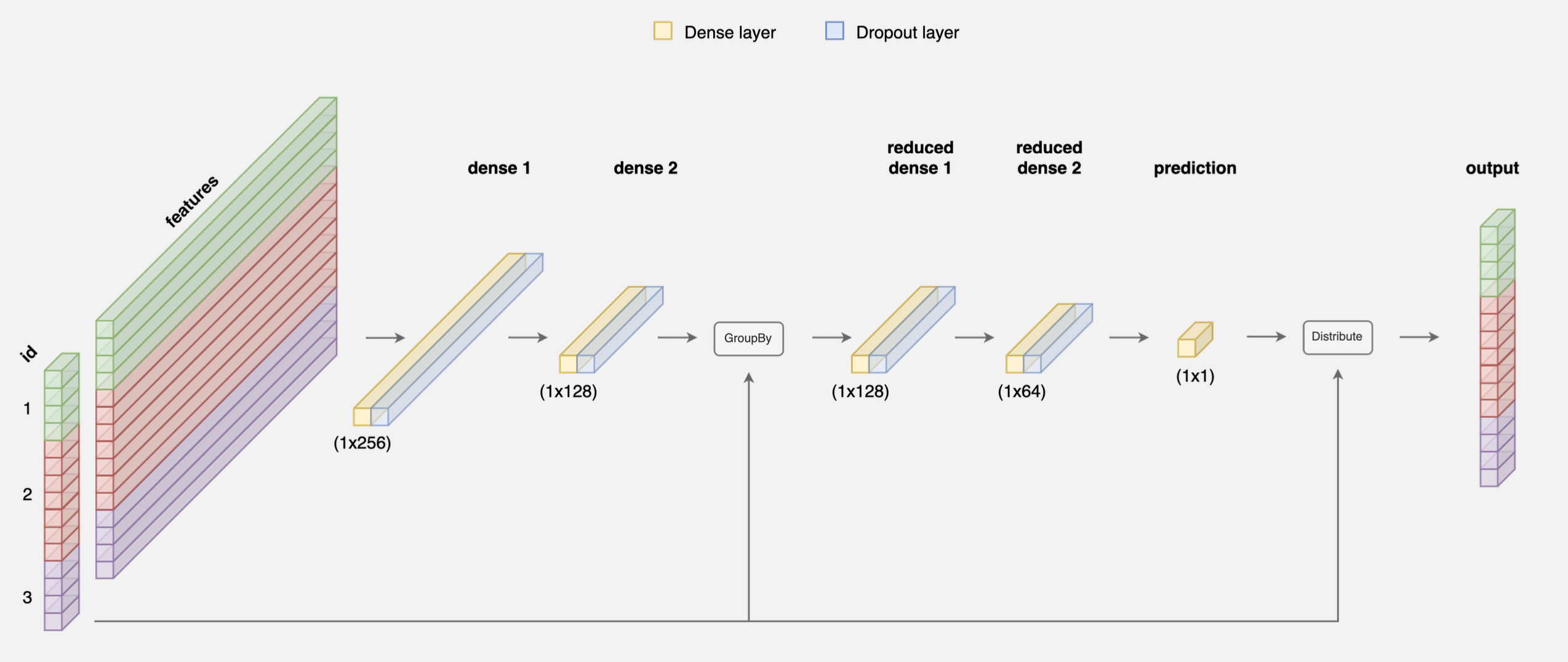
For some modelling exercises, input data is at a different granularity level than the target.
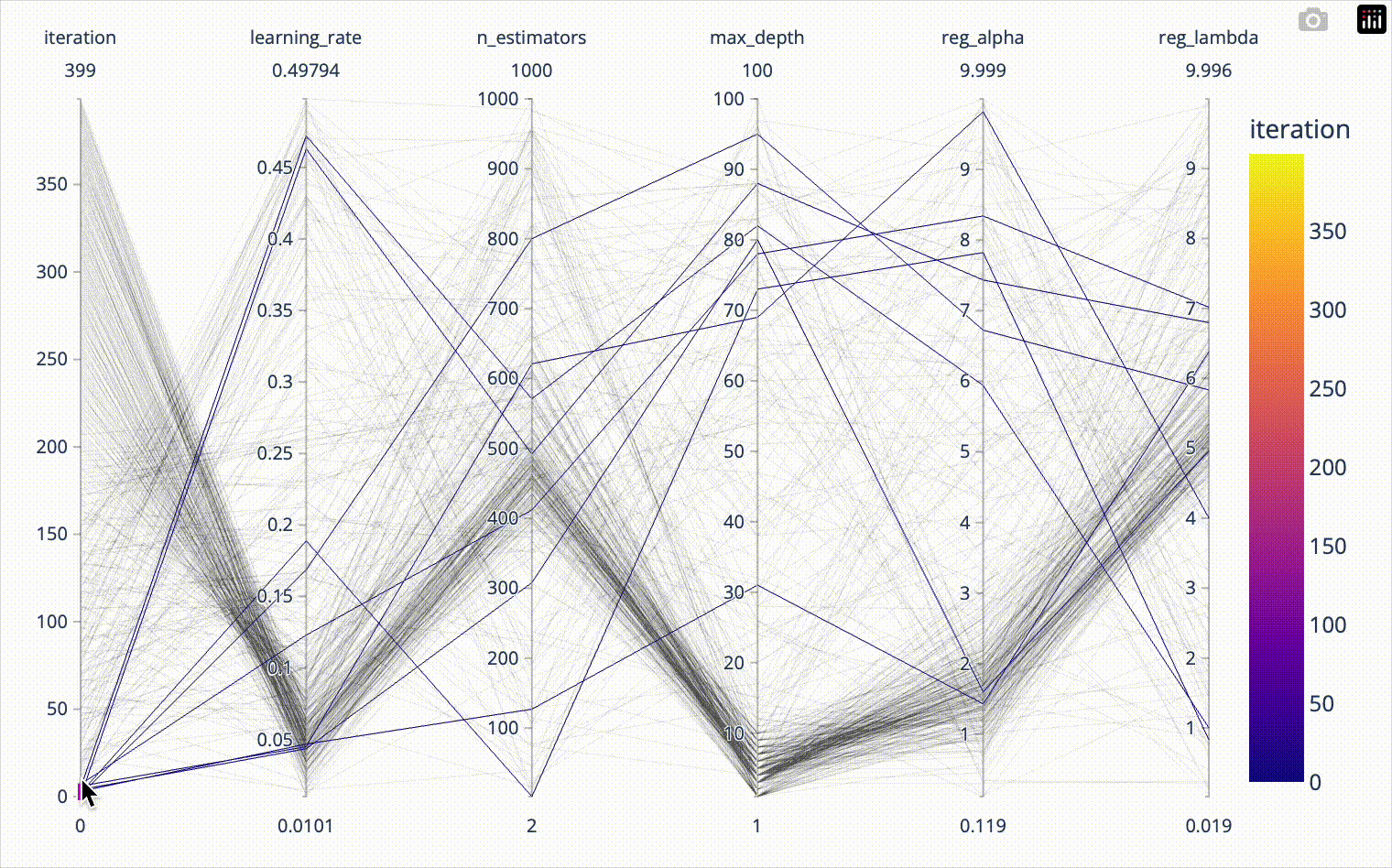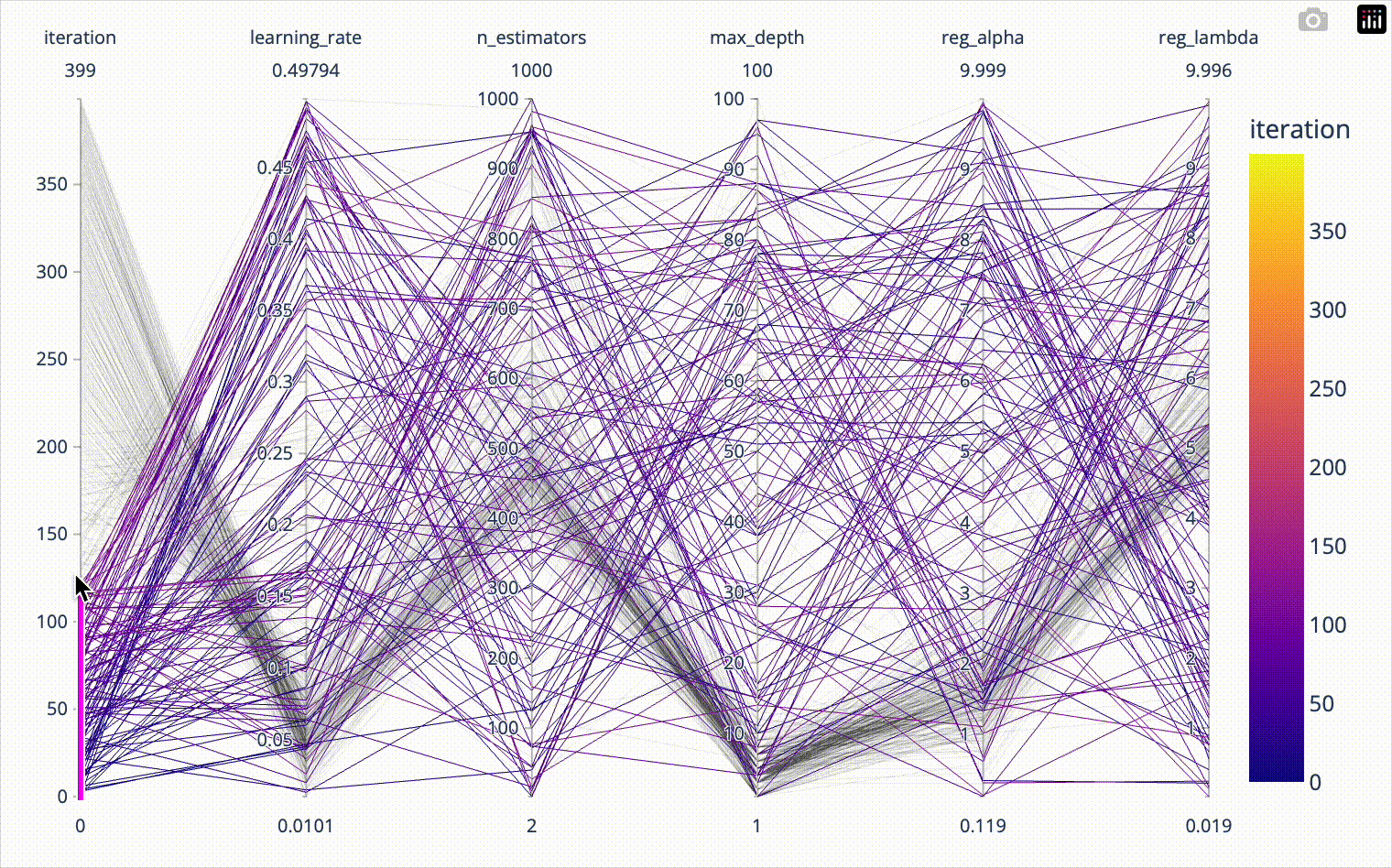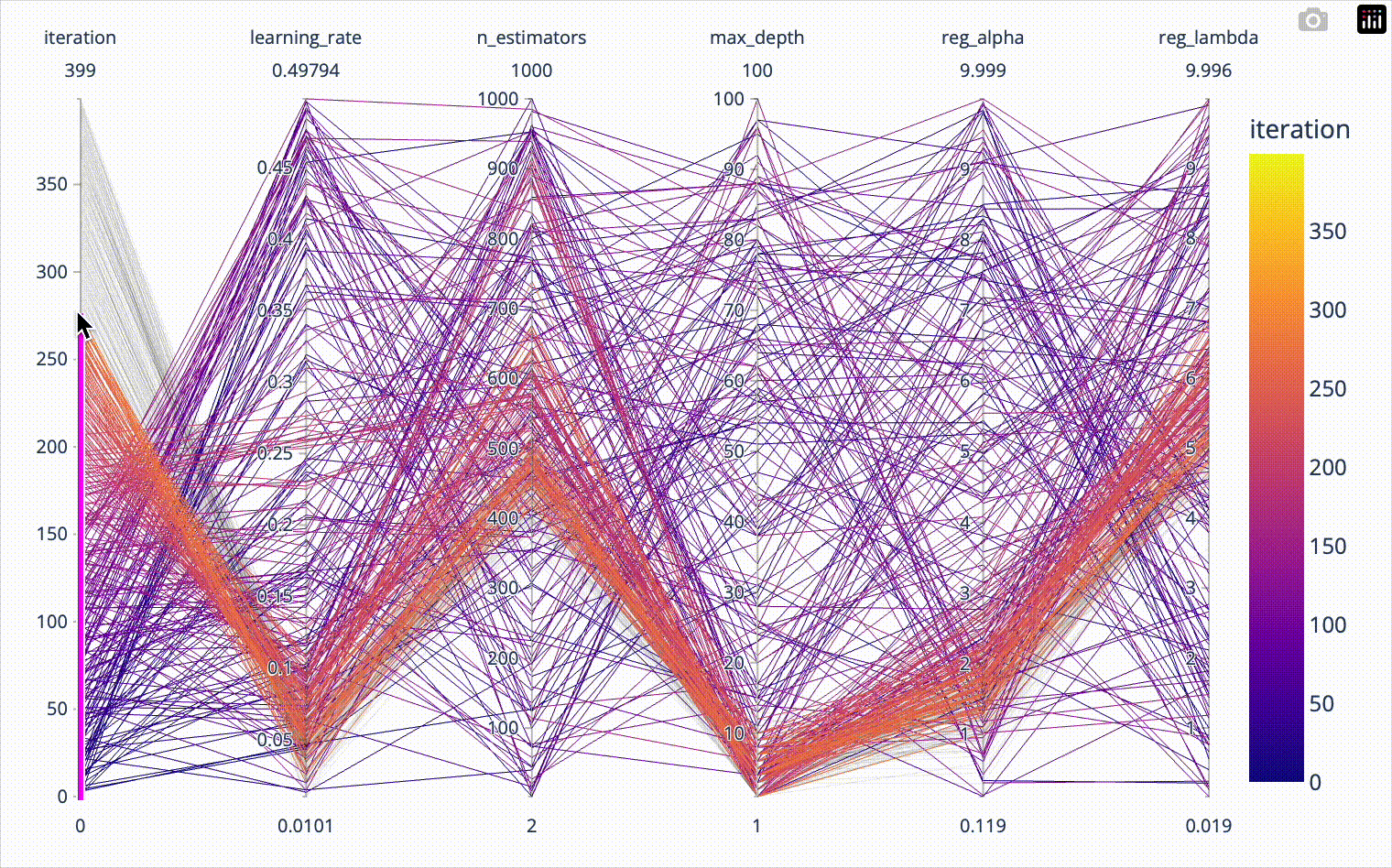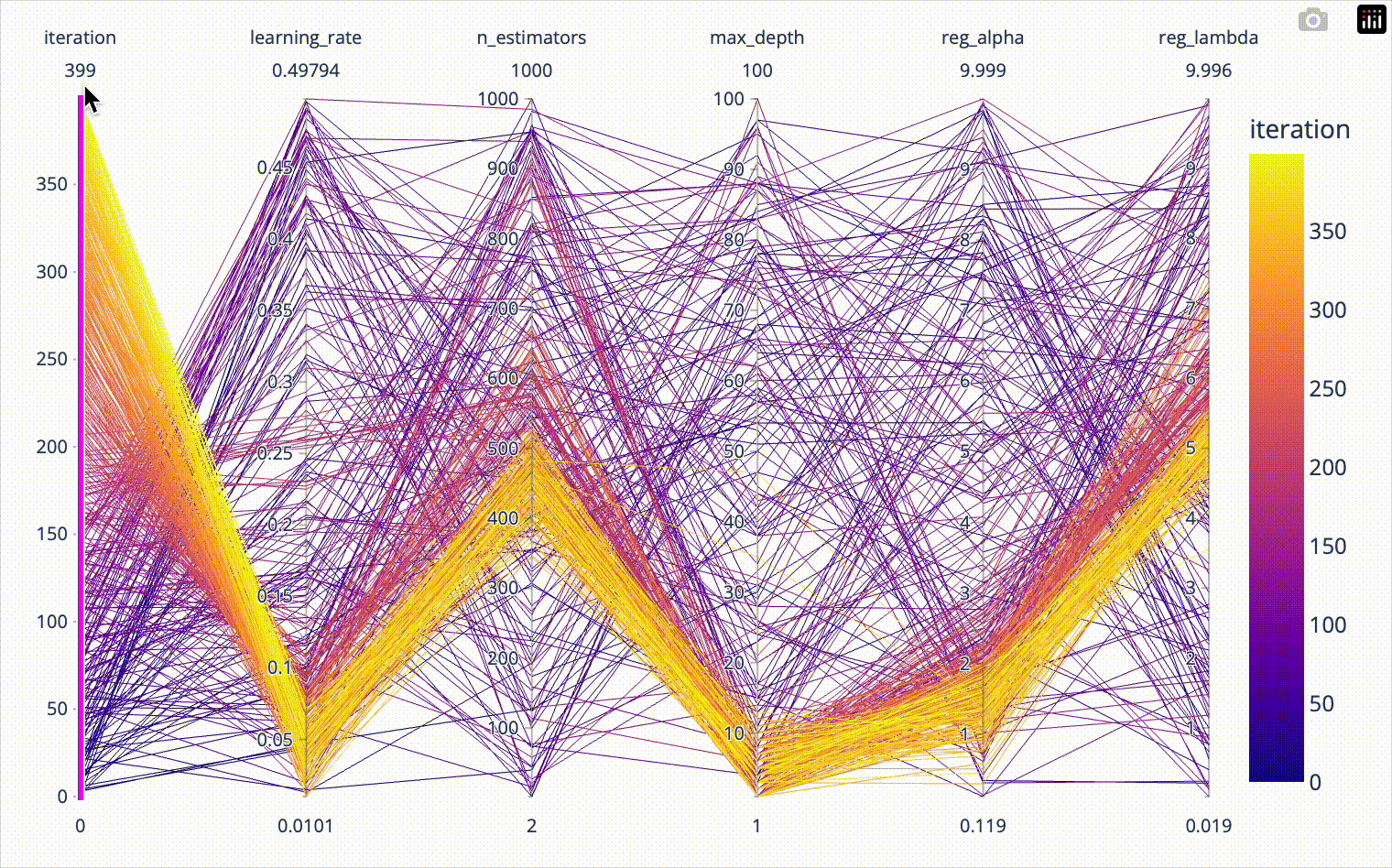
Ask-and-tell: How to use Optuna with Spark
Optuna is a hyperparameter optimisation framework that implements a variety of efficient sampling algorithms. Although using Spark to distribute the optimisation task is not…
Deduplication of records using DedupliPy
Deduplication or entity resolution is the task to combine different representations of the same real world entity. The Python package DedupliPy implements deduplication…
Distributed hyperparameter tuning of Scikit-learn models in Spark
Hyperparameter tuning of machine learning models often requires significant computing time. Scikit-learn implements parallel processing to speed things up, but real speed…
Finding duplicate records using PyMinHash
MinHashing is a very efficient way of finding similar records in a dataset based on Jaccard similarity. My Python package PyMinHash implements efficient minhashing for…
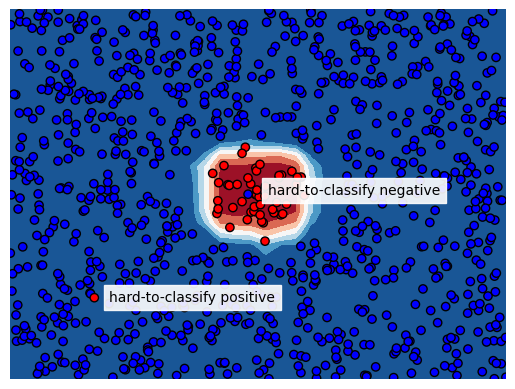
Hard-to-classify datapoints in imbalanced data problems
Classification for imbalanced data problems is hard; it requires paying attention to balancing classes when training and choosing the right model performance metric. Many…
Reduce data skew in Spark using load balancing
Data in a Spark cluster is divided over partitions. Two things are important about partitioning. First of all, partitions should not be too large. If a partition is too…
Taxonomy feature encoding
Features like zipcodes or industry codes (NAICS, MCC) contain information that is part of a taxomy. Although these feature values are numerical, it doesn’t necessarily make…
No matching items